稳定 70 万长连接的优化记录,妥妥的实战。
前言
本次压测是为了测试单个节点下,直连 MQTT 接入服务的连接承载力。
模拟方式
按正常线上设备模拟业务交互,TLS 双向认证,消息量如下:
MQTT PUBLISH
心跳
20bytes,间隔 15 秒
状态上报
500bytes,间隔 1 分钟
MQTT PING
2 分钟一次
业务心跳与状态上报为最主要的两类消息,心跳包 15 秒一次,与真实设备一致,这里的频率比例设置为了 8:2,主要考虑状态上报一般需要先下行控制报文,才被动触发。
这里由于下行触发的代码改造工作量较大,仅模拟“设备上报状态、服务端给予响应”的业务交互过程。
压测过程
首先,我们仅开启 MQTT PING。
大量 TCP 断连
建连时发现连接数上不去,大量断连,观察客户端日志发现大量未 ack 的 PINGREQ(服务端使用 Netty IdleStateHandler 处理读超时),应该是服务端资源不足以处理心跳的 PINGRESP 导致的,于是适当调大 Netty I/O 线程个数(8 改 64)。
SSL 握手超时
更新后重试,发现客户端大量 SSL 握手超时:

应该只是表象,查看服务端日志,线程耗尽:

我们查找使用“Message-Event-Worker”所属线程池的代码。
第一处的逻辑为,收到 PubAck 报文,取消 QoS 1 重发任务:
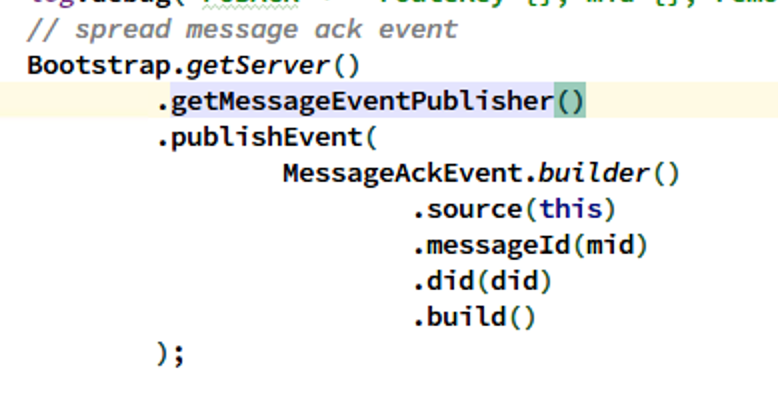

第二处 MQTT CONNECT 成功后写路由表:

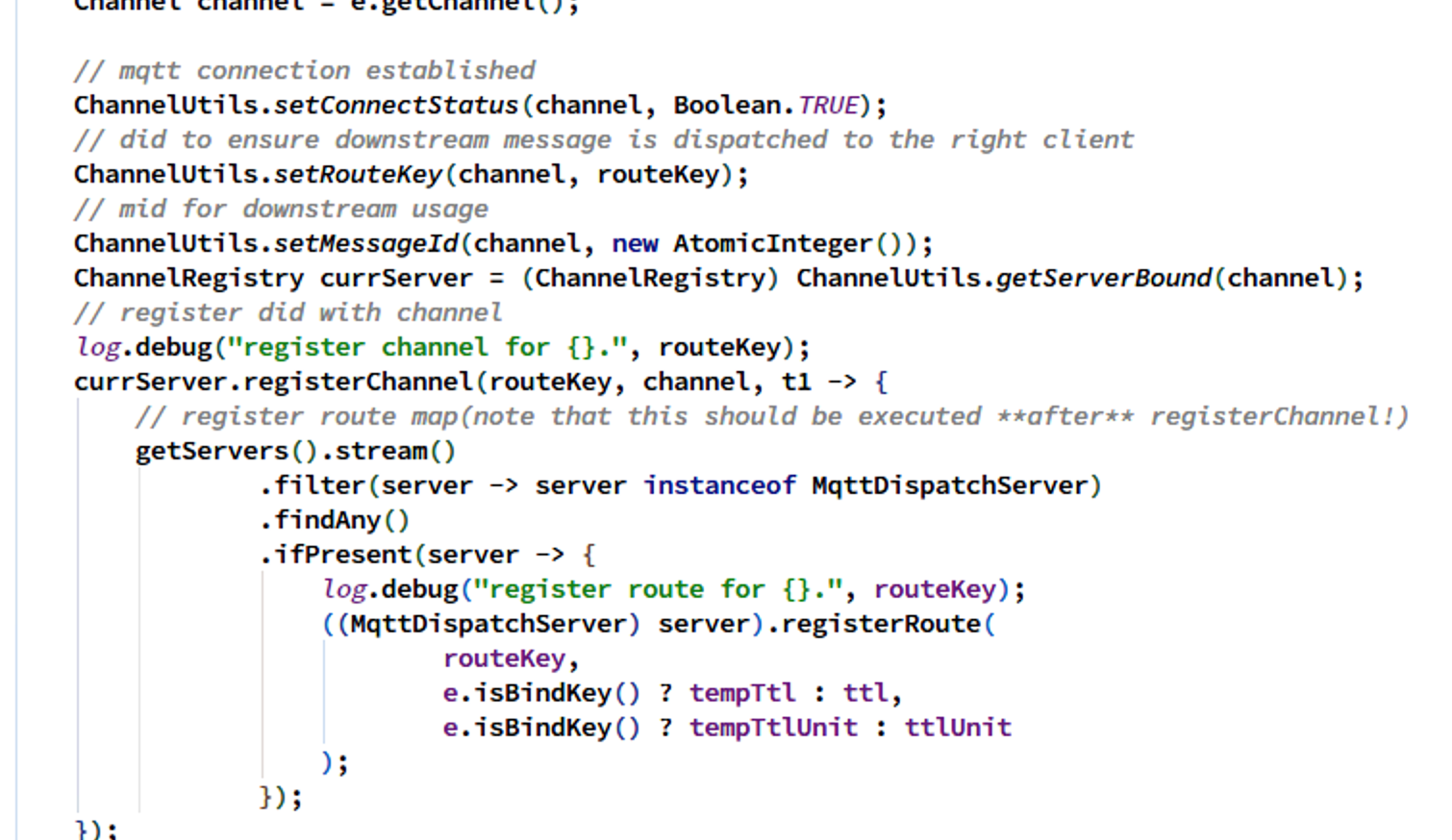
第三处,连接断开删除路由表:


第二处有打日志,排除;client 暂未实现 PUBLISH 报文,第一处排除,故报错为第三处,即大量连接断开事件打满线程池队列。
查看服务端和客户端的 SSL 握手超时,均为 20 秒:

那么原因应该是建立大量连接,SSL 握手超时,导致大量 TCP 断连,触发大量 channelInactive 逻辑所导致。我们尝试调大 Message-Event-Worker 线程池的队列大小(8 改 10240)后问题暂时解决。
Client 内存配置问题
压测过程中还发现模拟设备的 Client 端出现进程被 Kill:

使用 dmesg -T| grep -E -i -B100 'killed process' 查看发现是 cgroups 限制 2G,而 Client 启动参数也是 2G,系统本身还要一定内存,所以被 Killed 了,调大 MQTT-Client 内存限制并设置 -Xmx 小于容器限制后重试。
Memory cgroup out of memory: Kill process
线程池耗尽
重试发现 Message-Event-Worker 线程池依然报错:

可以看到,队列依然溢出了,走到了拒绝策略中,我们调整核心线程数(4 改 256)。
HTTP 连接不足
再次重试,这次直接报鉴权服务连接数问题:

观察鉴权服务,load 很低,基本无压力:

持续一段时间后报错消失:

观察 MQTT-Server CPU load,发现在 19:34 附近 CPU load 飙升,之后恢复正常:

之后也偶现同样的报错日志:

调用的鉴权服务接口是内网 HTTP 接口,使用 AsyncHttpClient,其底层使用 Netty 传输,我们将其连接池调大(per host 100 改 1000)。
Client 可用端口不足

Server 端由于大量客户端断开导致 Message-Event-Worker 线程池耗尽:

果然还是要关心一下断连的逻辑。
查看端口限制:

观察连接数,果然客户端到 28000 个连接左右就上不去了:



这里需要注意,重启会有很多 TIME_WAIT 端口不能用,需要等待一分钟(默认),虽然可以适当调小,但这里先不调整:

6 万连接,解决端口问题
我们先解决端口问题,调小客户端容器的连接数,之后稳定连上 6w 客户端,使用 top -H 查看 CPU load 占比较高的线程,通过 jstack 锁定 Log4j 使用的 Disruptor 缓冲线程的 CPU 占用较高:





继续调大线程池队列(10240 改 102400)大小暂时解决一下报错。
15 万连接,内存瓶颈
我们往上继续加连接到 20 万,发现之后是 SSL 加解密和 GC 线程占用较高(CMS):



到 15 万连接时出现连接超时断开,其中 client 端 TCP 连接一直上不了 2 万(会有断连):

server 端报错如下:

集中在 18:19 附近集中出现报错,之后恢复正常,连接数最终达到 20 万附近,但并不能稳定在 20 万整,不断有超时重连:

观察日志发现通过鉴权的有效连接实际上不到 20 万,只有 15 万左右:

其他连接还在不停的超时然后重试。
CPU load 过高的几个线程情况:


观察 GC 情况,Full GC 次数明显增多:

可以看到,GC 压力是比较大的。
由于频繁 STW,导致 Redis Client 等也开始超时报错(Redisson 使用 Netty 作为网络层,I/O 超时):


CPU load 图:

我们停止 Client 后,Server 端大量断连进入 close 逻辑,原本维系的 FullGC 终于扛不住了,触发了 OOM:

我们分析内存 dump,发现都是正常的建连所需对象:

如图所示,每个 SSL 连接都对应一个 OpenSslEngine 对象,缓存 SSL 通道的证书等信息:

且每个连接都会绑定一个 EpollEventLoop:

显然内存本身不够用了,现阶段瓶颈可以通过增大内存分配来解决。
由于只是 PING 报文,Netty 堆外内存使用无变化,且已池化,先忽略:

我们作以下调整:
调整 JVM 参数,最大堆由 2G 改成 5.4G(GC 暂且继续使用 CMS)
减少 Server 端日志打印以降低 Log4J 线程的 CPU 占用
加上断连事件的耗时统计(即 Server 端的 Message-Event-Worker 线程池在处理 channelInactive 时的任务执行时间)
添加对 Netty 线程组的队列任务数统计

20 万连接,大量断连带来的问题
然后重试 20 万连接,发现在 20 万连接的水平上,一旦有 Client 批量断连,触发 CPU 到达高水位,那么其它 Client 也可能由于超时未收到响应而断连,断连后 Client 会尝试重连,不断的重试会最终打满 CPU 造成雪崩,Redis、Zookeeper、HTTP 等 client 大量超时,之后出现 Full GC,系统根本自愈不了:

且由于不断新建连接,会耗费 OpenSSL 等库的堆外内存使用,如果内存分配不合理,为堆外内存预留的资源过少,可能出现进程被 OOM-Killer 干掉的情况:

我们的经验是大概留接近 -Xmx 大小的堆外内存,比如 8G 的限制,则一个合适的堆不要超过 5G。
基于上述,我们需要对大量断连和建连的情况分别作限流考虑,实施过载保护,这里我们停下来认真思考了服务端的代码优化。
代码优化
优化 Channel 注册表数据结构
服务端会保存设备 ID 与 Channel 的映射关系,之前的做法是将设备 ID 作多层散列,后来发现这里其实最关键的是减少竞争,故将原有的单个 Map 分解为多个对象,通过预先 hash 散列拿到数组下标值从而拿到 Map,再通过 JDK 的算法拿到 Channel 对象,避免多个线程对同一个 ConcurrentHashMap 的并发访问,减小粒度。
原结构:

新结构:

之前的代码逻辑是同一个设备 ID 可以保持多个连接,这里去掉了这部分逻辑,改成新连接会迫使旧连接断连:

优化断连时对路由表的操作
删除路由表操作接近 100ms 耗时,在大量断连时效果不佳,Redisson 底层的 Netty 线程池不够。我们使用 Pipeline 优化 Redis 的网络访问,优化大量断连时的性能,减少 CPU 占用。
原有逻辑,每次断连事件都进行一次网络 I/O:

现有逻辑,使用队列进行削峰:


利用 Redis Pipeline 优化性能:

建连过载保护
我们的逻辑是,触发了过载事件,则 spread 到关心它的 Listener,从而触发相应的逻辑,比如关闭端口监听以防止新的建连等。


40 万连接,加配置
将服务器配置改成 16C 64 G,40 万连接情况下,6G 堆,堆外大概占用 5G,出现 Full GC 2 次(图中 CPU 过高的时间段),之后稳定:




20G 大堆,开启消息上行
之前 Client 没有开启 PUBLISH 报文,仅 MQTT 的 PING 来保活,现改为 20G 大堆,开启上行 PUBLISH 报文。
建连后发现 CPU 占比高的线程为 Kafka-Producer 的 I/O 线程,查看源码发现 KafkaProducer 线程安全,默认使用一个 I/O 线程进行发送,先将消息放入本地 buffer,再批量发送至 broker,并且检查状态回调 Callback:

优化 KafkaProducer
修改 Kafka 配置,开启批量发送(linger),关闭 retry,改 acks 为 1 保证 Leader 持久化成功即可,加快回调速度:

效果不错:

70 万连接,优化对象创建
我们加到 70 万连接,客户端未发现断连,服务端无报错:

CPU 维持在 68% 上下:

内存使用如下:

网卡入站速率:

Kafka 生产速率:

我们等待一段时间,发现很平稳,无断连。
考虑到下行消息并未开启,若开启可能使 CPU 占用升高很多(甚至翻倍),所以不能乐观。
现在主要的方向为“如何尽可能减少 CPU 占用,在不撑满 CPU 的情况下支撑更多连接”。
70 万连接平稳后,查看 jstack:

发现 G1 GC 线程和 Kafka Producer 是占用偏高的几个线程。
尝试优化如下:
- 减少对象创建,比如固定对象使用同一个引用、取消使用构造器模式,改为直接 new:


- 增大 G1 停顿时间期望值:

- Kafka 的 linger.ms 调为 10ms
先不增加下行消息,仅作以上优化,效果如下:

没啥变化,还是 GC 忙:


Kafka I/O 线程繁忙程度:

查看 GC 日志,发现 GC 频率大概间隔 5 秒一次 GC,耗时都在 1 秒内:

GC 调优
我们明确方向为以应用程序吞吐量的降低换取高在线数,尝试:
- 将 G1 的年轻代调整为 20% 占比(-XX:G1NewSizePercent=20)
- 将 STW 期间的并行线程数从 13 调大至 20(-XX:ParallelGCThreads=20)
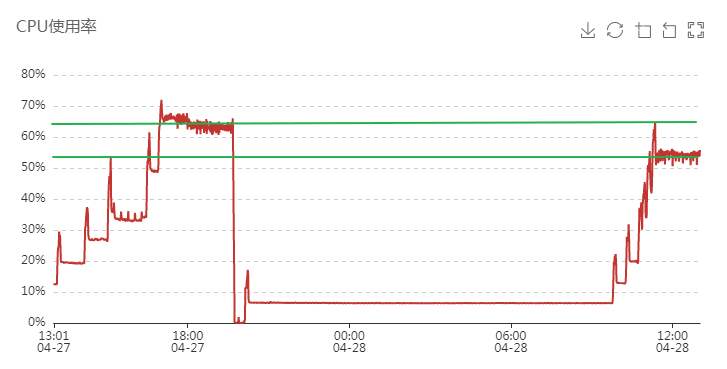
其他条件不变,同样加到 70 万连接,发现 CPU 下降了近 10%:
查看 GC 日志:
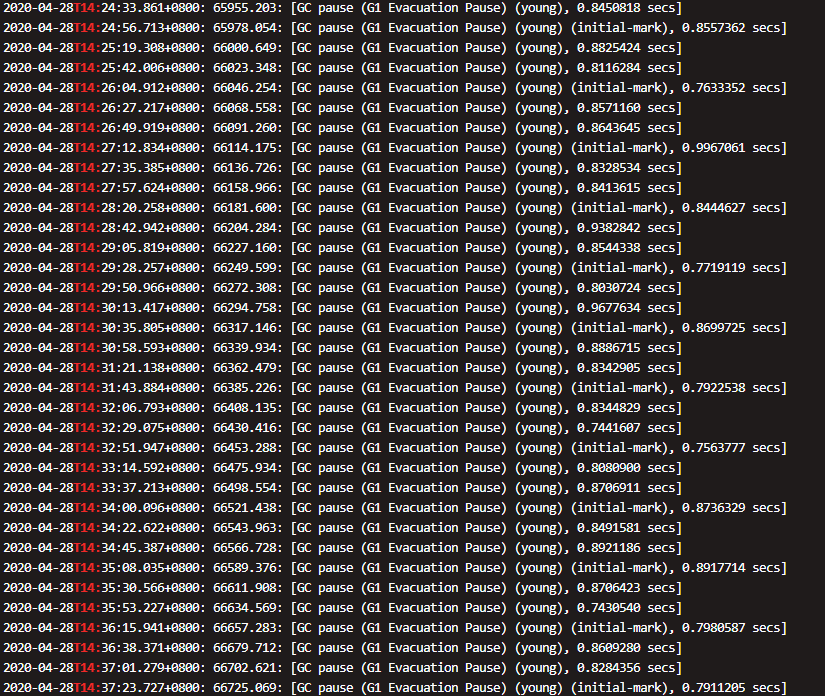
可以看到,频率下降了,STW 时间变化不大,达到了我们的目的。
我们继续用大 young 换 CPU 使用率,增大停顿时的线程数,并参考 官方调优文档 减少并发的 work 数量,增加 RSet 更新暂停时间占比,增加停顿时间期望:
- -XX:ParallelGCThreads=32
- -XX:G1NewSizePercent=30
- -XX:MaxGCPauseMillis=500
- -XX:G1RSetUpdatingPauseTimePercent=30
- -XX:+AlwaysPreTouch
或者更激进地完全将 RSet 的更新放进停顿中去:-XX:-G1UseAdaptiveConcRefinement -XX:G1ConcRefinementGreenZone=2G -XX:G1ConcRefinementThreads=0,需要谨慎开启,因为这可能会导致长时间的停顿。
检查代码还发现,上行的 PUBLISH 报文和 CONNECT 报文的处理是交给业务线程池处理的,但 CONNECT 报文需要异步请求鉴权服务,其余均为内存操作,PUBLISH 需要请求 Kafka,但也是异步的,所以将这里的异步改为同步使用 Netty I/O 线程池去处理,减少一次线程切换。



下行时也去掉业务线程池:

再次尝试:

又低了 10%,但是毛刺严重,不过由于我们不注重低延迟,STW 只要持续时长够短,CPU 高一点无所谓。


增加消息下行
检查代码,发现可以将下行 QoS 任务的设置异步化,并且打散任务注册,减少并发度:
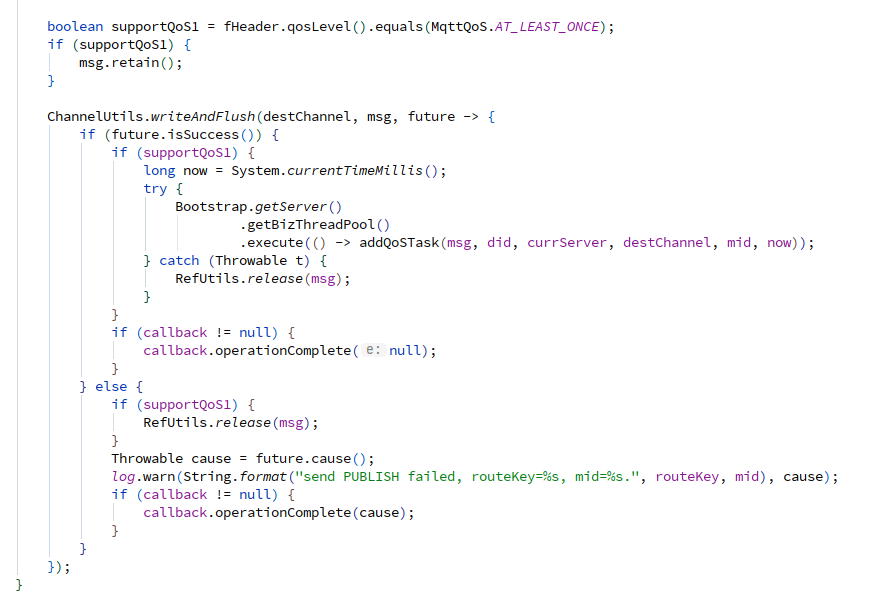
用同样的思路减小 QoS 任务注册表的粒度:

43 万连接时出现 QoS1 重试:

由于 ack 确认后,“取消重试任务”的线程是异步的,所以存在取消重试不及时的问题。
60 万连接时出现 Mixed GC:

70 万连接后,CPU 负载如下:

内存使用:

GC 频率:

停顿时长可以接受,时间与 CPU 毛刺基本对应。
Kafka 的生产速率大约为 6 万/秒:

客户端无断连:

QoS 重试比较频繁,重试任务的逻辑是在写成功 outbound buffer 后 3 秒内还未收到 PUBACK(以 Netty 的 channelRead 成功,切换到 BizThreadPool 后取消 QoS 任务为准),则进行重试。

Full GC 导致大量断连
过了一晚上,查看曲线图发现了一次大量断连重连:

查看日志发现有 FullGC

之前伴随一次 MixedGC(to-space exhausted):

可以看到,Full GC 之前有一次 Mixed GC,这代表 G1 收集器完成标记开启 Mixed GC 并准备清理老年代之前,内存就已经被耗尽了。我们需要让 Mixed 更迅速的收集。
Evacuation Failure 消耗了 860ms,可见转移失败的代价比多执行一些并发标记周期高很多。
一般来说,to-space exhausted 之后 FullGC 就不远了。
查阅相关资料,总结了以下调优方式:
- 通过
-XX:InitiatingHeapOccupancyPercent这个参数让 G1 GC 更早得启动 Mixed GC,默认占用整个堆的 45% 时才会开启 Mixed GC。不过,这个参数也不能调得太小,否则会导致过多的并发收集及 Mixed 收集,增加停顿时长。 - 通过调整
-XX:G1MixedGCCountTarget增加每次 Mixed GC 中老年代的处理数量。 - 调整
-XX:ConcGCThreads增加用于并发收集的 GC 线程个数(增加了 CPU 消耗),需要权衡。 - 有时候转移失败是由于 Survivors 中没有足够的空间容纳新晋升的对象,考虑增加
-XX:G1ReservePercent。
我们的调整如下:
- -XX:ParallelGCThreads=16
- -XX:InitiatingHeapOccupancyPercent=30
- -XX:G1MixedGCCountTarget=16
- -XX:ConcGCThreads=6
- -XX:G1ReservePercent=15
由于之前没加 -XX:+HeapDumpAfterFullGC 导致没有 dump 可分析,我们这次加上。
其它
增加 Kafka 消费速率
由于 PUBLISH 消息最终都会到 Kafka 中去,而如果消费者消费不过来,会出现业务交互上的超时,我们可以考虑增加并发度(consumer 线程数)和设置批量消费(还可以设置批量消费大小)。

实测增加并发度并不会大幅改变消费速率,但设置批量消费会大大加快。在消费逻辑为空的情况下,并发度为 10,关闭自动提交 offset,不设置批量消费时消费速率为 2k/s 左右:

开启批量消费,设置一次 pull 100 条消息,默认最大一次拉 50M 消息(如果单个消息体积过大可以尝试调整)消费速率可以达到和生产速率相同的 6w/s:

防止 Kafka 堆积造成磁盘不足
记得开启定期清理的配置(线上默认保留 1 天),否则在生产过快的情况下可能堆满磁盘:

一旦 Kafka 堆满,会导致 Client 出现以下问题(压测过程中出现过):


增加 RocketMQ 生产速率
业务服务处理完消息,会下行生产 RocketMQ 消息,可以利用上 Kafka 的批量消费,进行批量生产:

上图最后对 result 的判断是没必要的,RocketMQ 客户端只要不报错,就可以认为发送成功,不需要报错,特此说明一下。
增加 RocketMQ 的消费速率
RocketMQ 也开启批量消费即可。
总结
70 万连接,各指标如下:




Kafka:

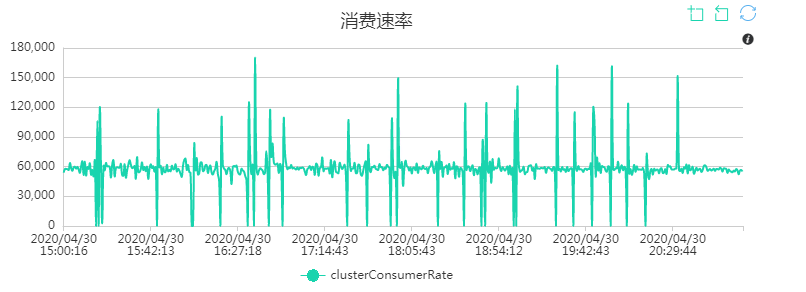
RocketMQ:

集群消费速率暂未优化,这里就不给出截图了,实际下行消息应当比当前的水平更高,可以后续优化。基本思路还是充分利用 CPU 进行 STW 期间的回收,减少 STW 时间,以一定的吞吐量降低的代价(只要不掉线)换取高在线数。