在分布式环境下,很多场景下都会需要获取唯一的 ID。
背景
架构
团队某项目使用 MySQL-5.6.28 数据库存储业务数据,均使用 InnoDB 引擎,其中:
- 考虑到某些数据域的数据量规模,对对应表进行了数据分片,目前使用一致性 Hash 算法管理 32 个 MySQL 逻辑 database 的路由行为,且通过添加虚拟节点以避免数据倾斜问题(放大系数 256,共 8192 个节点),使用简单的 Hash 算法取余作 100 张表的路由,路由键根据表属性的不同而有所差异。
- 应用已微服务化,日后会根据业务发展需要,从数据域的不同维度触发,做进一步的微服务拆分。
业务
业务场景中,生成 ID 一般是在新数据的持久化过程作为主键索引,也有 MQ 消息需要唯一 ID 方便查询跟踪。当然,也可以在为线程、请求、事务、Session 等“分配唯一 ID”的场景下使用。
这要求我们的程序需要保证作为分布式环境中的某个节点,拿到的 ID 的唯一性,否则很可能造成问题(比如使用 ID 作为索引时数据库主键冲突问题)。
当前生成唯一 ID 的实现方式为应用在自身 JVM 进程内通过 JDK 自带 UUID 工具类生成,数据库主键为 varchar 类型。
具体代码如下:

现状调研
UUID
java.util.UUID 生成的 uuid 遵循 rfc4122 规范格式,长 128 bits 共 16 字节,randomUUID() 工厂方法返回 32 个 16 进制的字符,以 - 分割,”8-4-4-4-12” 总共 36 个字符。

各部分含义如下:
| 分段属性名 | 数据类型 | 字节位 | 含义 |
|---|---|---|---|
| time_low | 无符号 32 位整型 | 0-3 | 时间戳低位 |
| time_mid | 无符号 16 位整型 | 4-5 | 时间戳中位 |
| time_hi_and_version | 无符号 16 位整型 | 6-7 | 时间戳高位混合 UUID 版本号 |
| clock_seq_hi_and_reserved | 无符号 8 位整型 | 8 | 时钟序列高位混合UUID变种号 |
| clock_seq_low | 无符号 8 位整型 | 9 | 时钟序列低位 |
| node | 无符号 48 位整型 | 10-15 | 空间中唯一的节点标识符 |
以
xxxxxxxx-xxxx-Mxxx-Nxxx-xxxxxxxxxxxx为例,M 表示 UUID 版本号,N 的最高有效位的第 1~3 位表示 UUID 变种号。N 描述如下:
Msb0 Msb1 Msb2 描述 0 × × 保留,为了 Apollo 公司当年的 Network Computing System(NCS)中 UUID 算法的向后兼容性 1 0 × Leach-Salz 变种 1 1 0 保留,为了微软算法的向后兼容性 1 1 1 保留以供未来使用 M 描述如下:
Msb0 Msb1 Msb2 Msb3 版本号 描述 0 0 0 1 1 基于时间的版本 0 0 1 0 2 基于 DCE 的安全版本,带有嵌入的 POSIX UID 0 0 1 1 3 基于命名的版本,使用 MD5 散列 0 1 0 0 4 基于真/伪随机数的版本 0 1 0 1 5 基于命名的版本,使用 SHA-1 散列
JDK 默认使用 Leach-Salz 变种的版本 4 UUID 算法,即“基于真/伪随机数的 UUID 算法”,相关源码如下:


可以看到,UUID 使用静态内部类延迟初始化了 java.security.SecureRandom。
SecureRandom 调用平台相关的“随机数生成器” SPI 实现,在 Windows 下的实现类(Java 11)为使用确定性随机位生成器 sun.security.provider.DRBG,而类 Unix 系统下(如 Linux、macOS)则使用 sun.security.provider.NativePRNG。
NativePRNG(即 native pseudo random number generator,本地伪随机数生成器)产生伪随机数的算法默认为 jca 框架的”SHA1PRNG”,它基于操作系统的“熵源”得到随机数,之后作 SHA1 散列(由于密码出口限制的法律限制,仅作散列未作加密),而这个“熵源”(也就是随机因子的来源)是设备驱动背景噪声。
类 Unix 系统的“熵源”为 /dev/random 和 /dev/urandom 两个字符设备文件,二者均为密码学意义上的“安全随机源”,不同点是前者“熵池”空了会阻塞等待生成,安全强度高一点,而后者是非阻塞的,会重复使用已经用过的“熵源”,如果不想阻塞,可以配置 -Djava.security.egd=file:/dev/./urandom。
/dev/random返回的是小于熵池噪声总数的随机字节。FreeBSD 系统(如 macOS)实现了 256 位的 Yarrow 算法变体,前者也不会阻塞,且后者是链接到前者的,只是为了兼容 Linux 系统。
至于为什么要加一个
.而不是直接写file:/dev/urandom是因为一个 JDK 的 Bug。
至于上文项目中使用 UUID 的例子,实际使用了 urandom,未使用 random,大致逻辑如下:
UUID.randomUUID()触发 UUID#Holder 初始化,调用new SecureRandom()构造器- 构造器调用
getDefaultPRNG() - 触发 NativePRNG.INSTANCE 初始化,
initIO()加载/dev/random为 INSTANCE 的 seedIn,/dev/urandom为 nextIn - 之后 UUID 调用 SecureRandom 的
nextBytes()方法,触发 NativePRNG.RandomIO#mixRandom 的初始化(sun.security.provider.SecureRandom 类型),从 nextIn 读取到 mixRandom 的 state 中 - sun.security.provider.SecureRandom#engineNextBytes 通过 state 算出随机数,并更新 state
MySQL
MySQL-5 使用 InnoDB 引擎作为默认引擎,其通过 MVCC 提供一致性视图,支持完整的事务属性,兼顾性能。其底层数据存储按照 B+ Tree 组织聚簇索引,具有 unique 特性。
B+ Tree 聚簇索引结构如下:

InnoDB 引擎的存储结构如下:

通常 FileSystem 的 Block 大小为 4 KBytes,为性能考虑,InnoDB 引擎的最小管理单位则是 Page,大小为 16 KBytes(映射4 个 Block),而申请存储空间则以“区”(Extent)为最小单位,大小 1MB。这么做之所以能提高性能是因为如果数据根据主键键值按顺序存放,那读取这些 Page 将会是在一个连续的地址中,可以避免磁头旋转定位带来的大开销。
而 B+ Tree 的数据段(叶子节点)与索引段(非叶子节点)在 InnoDB 中是分为两段(Segment)的:
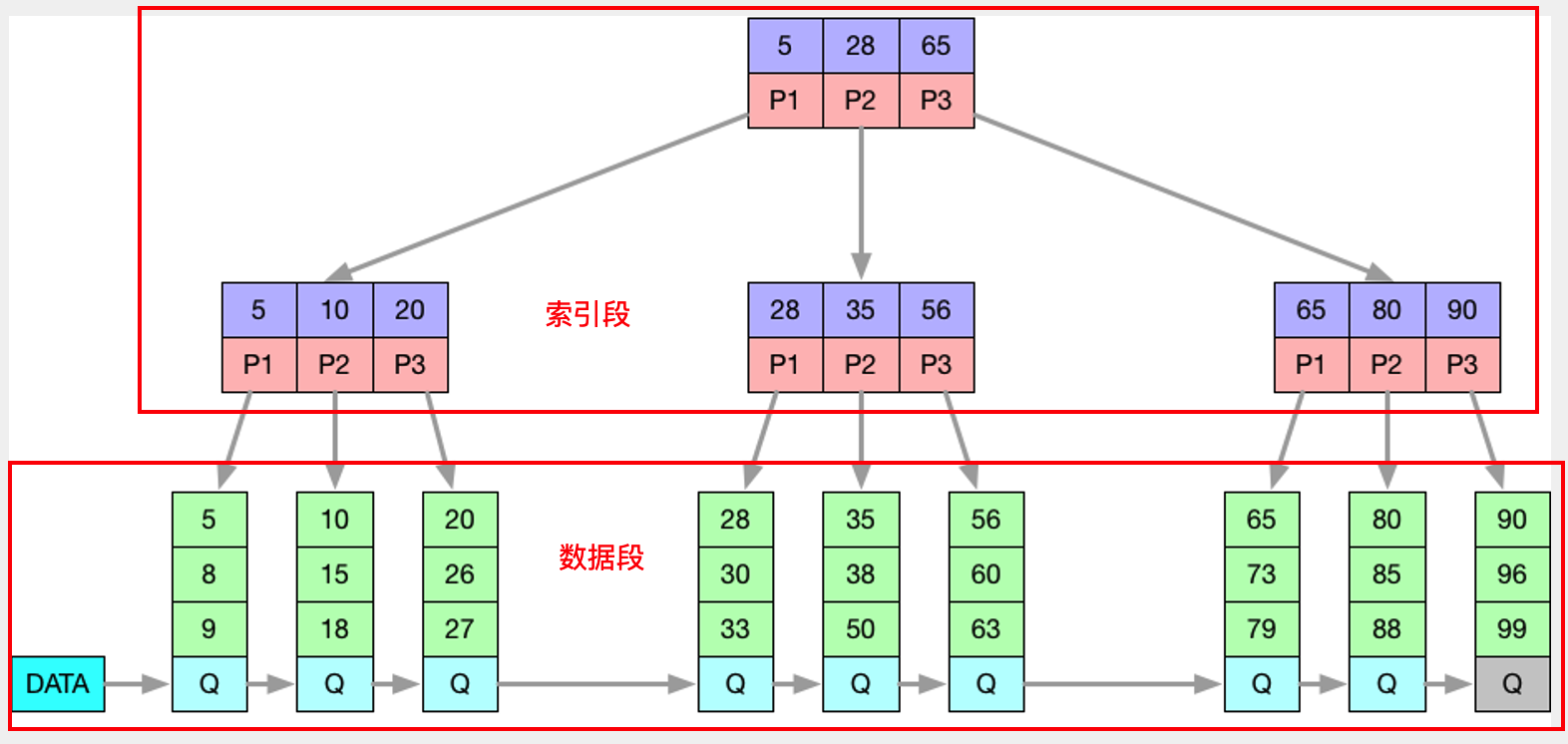
插入新值时,通常要考虑以下情况:
- 叶子 Page 和索引 Page 都没满
- 直接插入记录到叶子 Page
- 叶子 Page 满了,但索引 Page 没满
- 拆分叶子 Page
- 将中间节点放入索引 Page
- 小于中间节点的记录放左边、大于等于中间节点的记录放右边
- 叶子 Page 和索引 Page 都满了
- 拆分叶子 Page
- 小于中间节点的记录放左边、大于等于中间节点的记录放右边
- 拆分索引 Page
- 小于中间节点的记录放左边、大于等于中间节点的记录放右边
- 中间节点放入上一层索引 Page
可以看到,这里完全不涉及数据段或者索引段的 Page 分裂,在写满 page 后,使用新 page 继续顺序写。

注意,图中看似“分裂”了,实际表达的意思是“树节点”的分裂,磁盘页并未发生分裂。
乱序索引插入新值时行为如下:

注意到如果插入 11 时,其所在 page 满了,则会发生了 Page 分裂,InnoDB 会在最后创建新的 page,然后 搬迁 11 所在 page 一直到最新 page 之间的数据!其性能可想而知。
问题与痛点
- 由于 Java 默认使用的 UUID 算法有随机数因子,作为数据库表索引,随机的字符串影响了数据的插入速度;
- UUID 长 16 字节,且不连续,会造成数据库磁盘使用率低;
- 如果启动服务后马上调用 UUID 触发初始化,可能造成应用阻塞很久。
痛点更多在于第一点,即作为具备互联网业务属性的分布式微服务项目,在 ID 的获取与数据写入方面,性能要求会比较高。
熵池用尽
多次执行如下程序:
public static void main(String[] args) throws Exception {
System.out.println("Ok: " + SecureRandom.getInstance("SHA1PRNG").nextLong());
}多次执行,查看耗时:

在执行到第 18 次时遇到阻塞,时间长达 3 分多钟。
Tomcat 在启动时会调用 SecureRandom 初始化一个“Session ID 生成器”,如果阻塞太久,应用会迟迟起不来,所以才会存在上文提到过的使用 -Djava.security.egd=file:/dev/./urandom 来优化 Tomcat 启动速度。
具体逻辑请查看
org.apache.catalina.util.SessionIdGeneratorBase#createSecureRandom。
至此,解决这个问题的办法也已经很明了了,就是设置 -Djava.security.egd=file:/dev/./urandom 让程序使用 urandom,复用熵池。
测试一下:

可以看到,改用 urandom 后,不管怎么重复运行,都不会有阻塞的情况发生了。
如果程序只是使用 UUID,没有像例中直接使用 SecureRandom 的工厂类的话,就不会有这样的问题,因为 UUID 默认只会调用到 /dev/urandom:

生成性能
使用 JMH 测试框架测试吞吐量,预热 1 分钟,测试 3 轮,每轮 1 分钟,跑 3 遍流程,每遍都预热(预计耗时 16 分钟)。
public class UUIDBenchmark {
public void test() {
UUID.randomUUID().toString();
}
public static void main(String[] args) throws RunnerException {
int threads = Integer.parseInt(System.getProperty("ts"));
Options options = new OptionsBuilder()
.include(UUIDBenchmark.class.getSimpleName())
.output("./Benchmark_t" + threads + ".log")
.threads(threads)
.build();
new Runner(options).run();
}
}分别使用 1、4、8 个线程并发度,结果如下:
1 个线程

4 个线程

8 个线程

结论:性能很高,基本上都能达到 40万左右的吞吐量,由于不是关键瓶颈,这一项可以忽略。
CPU 2.5GHz 四核,机械硬盘,内存够用。
数据库插入性能
MySQL 为 5.6.28 版本,在本地 Windows 上测试。
建表语句如下:
CREATE TABLE `t_uuid` (
`id` varchar(32) COLLATE utf8mb4_bin NOT NULL,
`col_1` int(11) DEFAULT NULL,
`col_2` varchar(50) COLLATE utf8mb4_bin DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
CREATE TABLE `t_id` (
`id` int(11) NOT NULL,
`col_1` int(11) DEFAULT NULL,
`col_2` varchar(50) COLLATE utf8mb4_bin DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin由于 InnoDB 索引页和数据段是分开的,除主键外须多加几个字段看出效果。
我们控制 col_1、col_2 两列数据相同,在基础量级为空表、10 万、100 万、500 万和 1000 万的情况下,分别测试插入 100、1000、10000 条 UUID 索引数据的耗时情况,并关注磁盘占用,得到如下结果:
| 量级 | 连续插入 100 条 | 连续插入 1000 条 | 连续插入 10000 条 | 磁盘占用 |
|---|---|---|---|---|
| 空表 | 159ms | 874ms | 7817ms | - |
| 10 万 | 150ms | 880ms | 7684ms | 13.6MB |
| 100 万 | 150ms | 914ms | 7947ms | 123.0MB |
| 500 万 | 160ms | 1119ms | 11529ms | 570.0MB |
| 1000 万 | 165ms | 1267ms | 12175ms | 1243.0MB |
| 2000 万 | 221ms | 1219ms | 12564ms | 2121.9MB |
磁盘占用大小信息来自 INFORMATION_SCHEMA.TABLES 表的 DATA_LENGTH 字段,算法为聚簇索引页大小乘以 InnoDB 页数。
UUID 均预生成(使用数组下标取值)以保证结果不受生成 UUID 本身时间的影响。
插入时均使用 1 个 JDBC 连接、1 个线程进行测试。
我们再使用连续主键(应用自生成)来进行测试,结果如下:
| 量级 | 连续插入 100 条 | 连续插入 1000 条 | 连续插入 10000 条 | 磁盘占用 |
|---|---|---|---|---|
| 空表 | 160ms | 868ms | 7727ms | - |
| 10 万 | 183ms | 895ms | 8003ms | 5.5MB |
| 100 万 | 133ms | 870ms | 7781ms | 47.6MB |
| 500 万 | 196ms | 837ms | 7671ms | 226.7MB |
| 1000 万 | 205ms | 848ms | 7670ms | 423.8MB |
| 2000 万 | 296ms | 818ms | 7691ms | 871.0MB |
对比如下:



可以看出来,基础量级对插入耗时的影响在少量数据时影响不大,但是如果插入大量数据,就可以看出乱序和顺序索引的差距了。
导致出现这样结果的原因,是因为 InnoDB 在插入前需要先找到并从磁盘中读取目标 Page 到内存中去,这会产生大量的磁盘 随机 I/O,而因为写入是乱序的,InnoDB 又需要频繁地做 Page 分裂 操作,为新的 Row 分配空间。插入的越多,触发 Page 分裂的概率也就越大,自然耗时也越大。
磁盘利用率
确认已开启独立表空间:

根据上一节的统计结果,对比如下:

我们使用 innodb 工具 对 t_uuid.ibd 和 t_id.ibd 文件分别进行 Page 填充率分析。
innodb_space -f t_uuid.ibd space-extents-illustrate:
innodb_space -f t_id.ibd space-extents-illustrate:
产生如此大差距的原因就是因为使用无序索引会导致 InnoDB 频繁的 Page 分裂,Page 变得稀疏并被不规则地填充,导致磁盘碎片化严重。
结论
使用 UUID,尽管“熵池用尽”问题不存在,生成性能也很优秀,但是数据库的插入性能确实和连续索引有所差距(大批量插入体现的其实是概率问题),磁盘利用率也低很多。
所以我们总结我们的需求是:
- ID 获取要尽量方便可靠,保证高可用
- ID 获取需要高性能,需要时马上能拿到
- 由于不光数据库索引,消息 ID 也有类似需求,故 ID 需要全局唯一
- ID 要趋势递增
- 安全起见,ID 最好不能被预测
下面介绍解决方案调研结果。
解决方案
从架构上来说,解决方案可以分两种:
- 在应用自身 JVM 进程中根据一定的策略自生成 ID,自产自销
- 部署中心化的发号服务,Consumer 通过 RPC 等方式调用服务接口,完成 ID 的获取
这两种方案各有优缺点,前者无网络调用的消耗,如果策略是确定的,且没有依赖,那么天然高可用,而后者方便统一维护,升级和扩展很方便,解耦彻底,可以提供弹性扩容、容灾等实现高性能、高可用的服务,方便与现有微服务技术体系集成。
下面分别介绍两种架构方案。
一、“自给自足型”
这种方案,关键点在于寻找一种算法,让这个算法在不同节点算出的 ID 一定是不同的,并且还能保持整体的趋势递增,而这种算法的依赖项尽量要少。
1. 表基于 MySQL 自增主键
利用 MySQL 提供的 AUTO_INCREMENT 特性,我们可以很方便的得到一个递增主键索引,可以直接将业务表主键设为 AUTO_INCREMENT。
但是这种方案面临的问题也是有的:
- 如果需要对数据作分片,那么今后在多个 Shards 之间做数据迁移时(比如调整分片策略进行扩缩容),会受限制,部分 ID 可能冲突。而且在逻辑上,我们认为分片数据的主键在整块数据中也应该唯一,否则不能光使用 ID 在分片的数据中唯一确定一条记录(有时候会有扫描全量数据的可能,虽然绝大部分都会用 RouteKey);
- 项目使用 MHA 高可用方案,不管是主从复制,还是日后的海外部署时的数据同步,binlog 格式都有要求;
- 如果使用这种方案,只能解决数据库这一侧的问题,并不能解决获取“唯一消息 ID”等需求。
针对第 2 点,MySQL 目前支持的三种 binlog 格式为:
- ROW:基于行
- STATEMENT:基于语句
- MIXED:混合模式
使用 InnoDB 引擎时,基于 STATEMENT 的主从复制有以下几个问题:
- 在 MySQL 5.6.10 之前,STATEMENT 模式需要主、从的自增列定义得一模一样;
- 触发器或方法更新自增列的复制会失效;
- ALTER TABLE 中添加 AUTO_INCREMENT 列可能导致主、从的行数据顺序不一样。
查看生产库的配置发现 binlog_format 为 ROW,第 2 点可以解决:

综上,虽然第 2 点问题可以解决,但第 1、3 两点显然不能满足,且 ID 号是可以计算(预测)的,故这种方案一般是在表数据量不大的场景下使用,并不适合现有架构。
2. 基于 Snowflake 算法
Snowflake 是 Twitter 开源的分布式 ID 生成算法,结果是一个 64 bits 的 ID,结构如下:

- 1 位标识,Java 中 long 带符号,ID 一般是正数,最高位固定为 0;
- 41 位时间戳,存的是
(当前时间戳 - 开始时间戳)毫秒数,这里的开始时间一般可以设置为该 ID 生成器开始使用的时间; - 5 位数据中心标识;
- 5 位机器标识;
- 12 位序列,毫秒内的计数。
可以看到,这种生成方式是非常紧凑的,没有冗余的 bit,生成的 ID 按时间戳趋势递增,理论上支持 2 ^ (5 + 5) = 1024 个节点,可以使用 (1L << 41) / (1000L × 60 × 60 × 24 × 365) = 69 年,同一机器同一毫秒窗口内支持最多产生 2 ^ 12 = 4096 个 id。
Snowflake 算法理论上两种架构均适用,既支持自生成,也支持单独部署,而且 ID 号不能简单地被预测。
实际使用时,可以根据情况小幅度修改算法,满足业务自身的要求,比如 MongoDB 就是使用“时间 + 机器码 + pid + inc”的方式生成 objectID 的。
个人认为 Snowflake 更重要的是“基于时间达到趋势递增”这一思想。
但这种算法也存在问题:由于强依赖时间戳,故服务器 NTP 不能有问题,如果产生 时钟回拨,则可能生成重复的 ID。
二、自研发号服务
这种架构走的是中心化统一部署,将 ID 生成服务化的思路。
1. 直接使用 MySQL 作为服务
直接将 MySQL 作为一个基础服务看待,设置 AUTO_INCREMENT,利用 getGeneratedKeys() 方法获取自增 ID:

图中为一主两从高可用 MySQL 集群。
可是这种方案存在单点写问题,解决方式就是使用多个 MySQL 高可用集群,每个集群分给一个或几个服务使用,并且设置不同的 AUTO_INCREMENT 步长和起始偏移:

N 个集群,可以分配给 N 批业务,步长为 N。
比如使用三个集群,那么步长就是 3,若起始偏移分别为 0、1、2,则:
第一个集群产生的 ID 为 0、3、6、9……
第二个集群产生的 ID 为 1、4、7、10……
第三个集群产生的 ID 为 2、5、8、11……

这样就解决了单点写问题,而且消息 ID 的获取可以当作单独的一项服务去获取某个步长的 ID(与数据库索引相关的业务重复也不要紧)。
但缺点也很明显:不支持扩容,需要预先定义好步长,而且基于数据库的生成方案都有 ID 可预测问题,下面不再赘述。
2. 基于 MySQL 搭建服务
基于 MySQL 搭建 ID 生成服务集群,服务本身从 MySQL 数据库获取唯一的 ID,然后分发给 Consumer:

这种方案相比上一种直接使用 MySQL 的方案,多了一层中间层,由于 MySQL 可以结构化存储数据,这种架构的灵活度较高,可以在中间层为特定的服务定制 ID 号段。
3. 直接利用 Redis Incr
利用 Redis 的原子指令 incr 拿到自增数,然后在前面拼上时间戳:

这种方案同样需要考虑始终回拨问题,同时也要兼顾 Redis 的可用性问题,比如宕机恢复不能清零,故需要持久化,持久化则需要考虑性能问题,且由于 Key 固定,同样存在单点问题和被预测问题,虽然比 MySQL 性能高,但并没有 MySQL 灵活。
4. 基于 Redis 搭建服务

这种方案并不能解决 Redis 的单点写问题,只是能够通过预取的方式避免 Redis 写集中和一定程度上的宕机可用(取决于宕机前预取 ID 的剩余数量可以提供多久的发号服务)。
同时,服务化方案还可能存在一个问题,那就是多中心化部署时,如果需要同步数据,那很可能有性能瓶颈,虽然可以通过一些方案解决,但是要考虑的点更多。
三、开源方案
1. Leaf-Segment
Leaf 由美团点评技术团队开源,分为两种模式:号段模式(Leaf-Segment)和 snowflake 模式(Leaf-Snowflake),目前已经做了整合,可以通过配置选择。
号段模式下,服务不直接从 DB 取,而是通过代理层服务 批量预取,提高性能:
CREATE TABLE `leaf_alloc` (
`biz_tag` varchar(128) NOT NULL DEFAULT '',
`max_id` bigint(20) NOT NULL DEFAULT '1',
`step` int(11) NOT NULL,
`description` varchar(256) DEFAULT NULL,
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`biz_tag`)
) ENGINE=InnoDB;
- biz_tag:业务标志
- max_id:此业务当前分配的最大 ID
- step:步长
每个服务都会预先分配一个 biz_tag,通每个 biz-tag 的 ID 获取相互隔离,互不影响(不同服务获取到的 ID 之间是会重复的)。如果以后有性能需求需要对数据库扩容,对 biz_tag 分库分表即可。
更新号段的 SQL 如下:
Begin
UPDATE table SET max_id=max_id+step WHERE biz_tag=xxx
SELECT tag, max_id, step FROM table WHERE biz_tag=xxx
CommitLeaf 有个优化点,就是不等到号段用尽去更新号段,而是“未雨绸缪”地提前触发取用号段,做到上层调用时的无阻塞,很大程度上降低系统的 TP999 指标,减少“毛刺现象”,美团管它叫”双 buffer 优化”,即当号段消费到某个点时就异步的把下一个号段加载到内存中:

2. Leaf-Snowflake
Leaf 还有另一种模式,不依赖数据库,而是采用 Snowflake 算法,避免了 ID 被预测。
对于 workerID(数据中心 5 bits + 机器号 5 bits)的分配,使用 Zookeeper 持久顺序节点 的特性自动对 Snowflake 节点配置 workerID。
workerID 会以文件形式缓存在本地。


这种方案其实存在下列问题:
- 弱依赖 Zookeeper
- 时钟回拨问题
- 多机房部署问题
关于第 2 点,美团给出的方案是关闭 NTP 同步或者在时钟回拨的时候返回 ERROR_CODE 等时钟追上,或者做一层重试,然后作报警,更或者是发现有时钟回拨之后自动摘除本身节点并报警。核心代码如下:

我们再来考虑第 3 点,事实上,如果两个子网下的两台机器共用一个非当前网络的 Zookeeper,那么 IP + Port 其实是可能重复的,这种情况下只能在 Zookeeper 那台机器或者同网段机器部署一个 IP 获取的程序,通过接口获取到本 Leaf 节点在 ZK 所在子网下的 IP + Port 信息:

那么话说回来,事实上如果服务部署多个机房,且数据库数据是复制过去的(没有分片单元化),那么一定要使用同一个 Zookeeper 集群,否则 workerID 可能重复。
3. uid-generator
uid-generator 是百度开源的,Java 实现的,基于 Snowflake 算法的唯一 ID 生成器,默认的字节分配方式如下:

- 1bit sign:固定 1bit 符号标识,即生成的 UID 为正数;
- 28 bits delta seconds:当前时间,相对于某个时间基点的增量值,单位:秒,最多可支持约 8.7 年;
- 22 bits worker id:机器 id,最多可支持约 420w 次机器启动,内置实现为在启动时由数据库分配,默认分配策略为用后即弃,后续可提供复用策略;
- 13 bits sequence:每秒下的并发序列,13 bits 可支持每秒 8192 个并发。
uid-generator 内部通过 RingBuffer 环形数组存储信息,Uid-RingBuffer 用于存储 Uid、Flag-RingBuffer 用于存储 Uid 状态(是否可填充、是否可消费),实际上是将 Leaf-Segment 中的“双 buffer”整合到了 Uid-RingBuffer 中,并且使用另一个 Flag-RingBuffer 存储状态:

数组元素在内存中是连续分配的,可最大程度利用 CPU cache 以提升性能,但同时会带来“伪共享”(False Sharing)问题,为此,uid-generator 在 Tail、Cursor 指针、Flag-RingBuffer 中均采用了 CacheLine 补齐的方式填充:


实际上 JDK 1.8 提供了 @Contended 注解方便避免 False Sharing。
与 Leaf 使用 IP + Port 不同,uid-generator 中,worker id 使用从数据库获取的方式,可以避免上面提到的多机房部署时 IP 获取的问题(使用同一数据库即可)。
同样,uid-generator 内部也作了始终回拨的检验,只不过比较粗暴,其实可以参考 Leaf 的逻辑优化一下:

4. seqsvr
seqsvr 是对 万亿级调用系统:微信序列号生成器架构设计及演变 的 C++ 开源实现,微信使用 seqsvr 生成消息版本 ID,用于对比服务器与客户端消息版本的差异,据此来拉取新消息。
seqsvr 使用“号段”模式 + 中间层的架构,ID 保障的是 用户维度的唯一,不同用户之间消息版本的 ID 无关联,整体架构作了用户维度的单元化,中间层为归属本 Set 的用户服务,方便容灾隔离。

由于每个用户都有一个 max_seq,在中间层服务重启后,需要获取当前已分配的最大序列,而这个请求量是非常大的。微信做了个优化,对本 Set 用户进一步划分 Section,同一 Section 内的用户共用 max_seq,以此减小服务重启时的 I/O 量,从而减少时间:

由于微信是纯 2C 的 IM 产品,有其业务特殊性,这种架构不是很适合我们的业务,仅作了解。
小结
“自给自足型” 架构方案的优点是 没有网络调用,效率高,可用性和性能都很好,而且服务不存在强状态,可以无痛多机房部署,可能存在一些若依赖项,比如基于 Snowflake 算法的方案中,机器序号如果不预分配,则要从 Zookeeper、数据库等三方组件获取。
中心化服务有两种,一种一般会强依赖(或内聚)某个组件的某一特性,比如依赖 MySQL AUTO_INCREMENT。另一种为 Snowflake 变种,对三方组件的依赖和 “自给自足型” 架构方案一样为弱依赖。
为性能考虑,中心化服务方案一般会在 Server 端 预先批量生成 一批 ID,以减少阻塞带来的“毛刺”。
中心化服务的共同缺点是增加了架构复杂度,调用端依赖于 ID 生成服务的高可用性,毕竟是基础服务,需要在容灾方面周全考虑。
开源方案一般都属于中心化服务方案,且 Leaf 等方案在大厂成功落地,如今很多小厂也在使用,经过实际检验,比较成熟,可以避免很多坑,比如始终回拨、Cache Line 伪共享等,根据实际情况,可以选择性的采用,或者自研时将其优点借鉴过来。
迁移方案
由于数据库历史数据已经产生,我们需要考虑迁移方案。
完整迁移
步骤
- 修改代码,id 使用新方案生成;
- 执行老数据迁移,具体需要扫描全量表进行操作,可使用写接口、脚本或定时任务触发;
- 执行 DDL 更改 id 的数据类型为 bigint(可选)。
优点
- 磁盘使用率变高(当前数据量不大,很难体现);
- 如果当前数据已生成满 Page 页,则更改后能避免一部分插入时的页分裂(当前可能收效甚微)。
问题与解决方案
| # | 问题 | 方案 |
|---|---|---|
| 1 | IdGenerator#uuid() 方法在其它非生成主键的业务中也有调用 |
需要统计所有生成 ID 的方法调用点,新增方法,然后修改调用点代码 |
| 2 | 强依赖服务器时钟 | 1. 方法中将上次生成的时间戳与当前作比对,若发现回拨,则等待直到满足要求,期间工具类无法提供服务(如果只是秒级回拨,可以承受),可配置报警逻辑;2. 配置服务器 NTP 为不能回拨的模式(需要运维支持),或者干脆关闭 NTP 同步 |
| 3 | 上线后需要校验老数据是否迁移完,然后执行 DDL 才能成功 | 新增校验逻辑,扫描表,甄别新老数据 |
| 4 | 有的表有与其它表主键列关联的列 | 工作量,存在遗漏风险,须测试全面 |
| 5 | 需要扫描所有表 | 数据量不大时还好,可以选择流量低峰进行 |
| 6 | DDL 需要获取 metadata 锁,锁为表级,故执行时不能有大事务在进行,否则有挂库风险 | 项目目前很少使用事务的业务,且事务粒度不大,风险很小,关于会阻塞 DELETE、UPDATE,建议使用 pt-online 等工具进行修改 |
回滚方案
事前备份数据库,根据情况回滚代码和恢复数据。
直接切换
仅新增工具类方法替换现有逻辑,不涉及其他步骤。
优点
修改简单,不易遗漏,不影响老数据,回滚简单。
问题与解决方案
| # | 问题 | 方案 |
|---|---|---|
| 1 | IdGenerator#uuid() 方法在其它非生成主键的业务中也有调用 |
同上,略 |
| 2 | 强依赖服务器时钟 | 同上,略 |
回滚方案
回滚代码即可。
实际选型落地
没有最好的架构方案,只有最适合自己的。项目中我们实际选择落地的是“客户端自给自足”的方案,并在 Snowflake 的理论基础上做了修改:

- 机房标识来自环境变量,这里做了散列;
- 机器序号来自 MySQL 单表自增 ID,主键为无符号 int 类型,考虑 JVM 启动频率,可以满足要求;
- 毫秒内自增序列相比原生算法少了 3 位,支持毫秒内生成
2 ^ 9 = 512个 ID。
其实直接使用唯一机器序号也是可以的,当时考虑还会进行海外部署,为了减少跨 IDC 的调用,还是加上了机房标识。
生成结果示例:

依赖项
- 数据库(启动时)
- 配置中心(启动时)
- 环境变量
问题
InstanceId 问题
最初想直接使用 8 位实例 ID 作为机器号,但如果取环境变量中的实例 ID 是不行的,因为它本身是可能重复的,关于这一点,解决办法就是使用数据库生成。
具体为什么重复这里就不说了,涉及到代码隐私。
时钟回拨问题
这一点在程序参考 Leaf 的做法,一定程度上避免了。具体是当回拨不大时(当前设置为小于 5ms),会等待两倍差(比如回拨 3ms 则 sleep 6ms)的时间。
重启机器重新获取时,无法判断停机时是否回拨过(大概率不存在,因为进程重启是需要时间的)。
我们暂不考虑机器重启时的回拨,设置了 NTP 为关闭,添加了关键字日志告警(不使用主动 RPC 告警的原因是,由于生成器为工具类,这里不想过多要求使用方依赖告警服务或者 Spring)。

应用接入
ID 生成方式已封装相应工具类 IdUtils,默认单例。
项目接入只需引入 xxx-common 并添加以下项目即可:
- 配置文件:
- id.jdbc.url
- id.jdbc.driver
- id.jdbc.username
- id.jdbc.password
- 配置项:env(KV 形式,prod、test、dev)
- MySQL Driver 依赖
本地开发时,使用固定 AppId:

测试
生成性能
与前文中测试 UUID 的生成性能的方式一样,我们使用 JMH 进行吞吐量测试,结果如下:
1 个线程

4 个线程

8个线程

理论上 1 秒可以生产 1 × 1000 × 512 个 ID,这个测试结果接近理论值了。
磁盘占用
CREATE TABLE `t_new_id` (
`id` bigint(20) NOT NULL,
`col_1` int(11) DEFAULT NULL,
`col_2` varchar(50) COLLATE utf8mb4_bin DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin实测 2000 万级数据占用 938 MB空间,Page 占用情况如下图:

反省与思考
目前项目所有模块均已使用新的 IdUtils 工具类,需要肯定的是,在方案选择上,我们尽可能地选择了简单的、适合业务形态的架构方案。
但是事后反思这次落地,我们还是发现有以下不足:
接入便捷度上做的还不够好,或者说不够完整
目前增加配置项和 MySQL Driver 依赖的方式其实还比较繁琐,新应用接入还存在一些小成本。实际上最好能实现“一行 dependency 依赖”解决问题,做到零成本接入。为此,需要一些额外的工作量,比如开发 sdk 包,实现根据所属环境自动拿到 MySQL 地址信息等。
扩展灵活性不足
目前只考虑了递增 64 bits 整形这一种情况,并没有兼顾其它需求,比如获取其它长度、其它类型的 ID。但由于使用的是自生成的方式,这种情况能满足大部分需求,或者说最痛点的需求(即数据库 ID),毕竟不能为了当下一个不存在的需求徒增开发量,个人认为这样已经就足够了。
如果让我再做一次,有时间的话,可以往中心化 ID 生成服务的方向多思考,提供灵活度以及扩展性,满足不同需求。